Query Vectorization for Apache Hive in CDH
By default, the Hive query execution engine processes one row of a table at a time. The single row of data goes through all the operators in the query before the next row is processed, resulting in very inefficient CPU usage. In vectorized query execution, data rows are batched together and represented as a set of column vectors. The basic idea of vectorized query execution is to process a batch of rows as an array of column vectors:
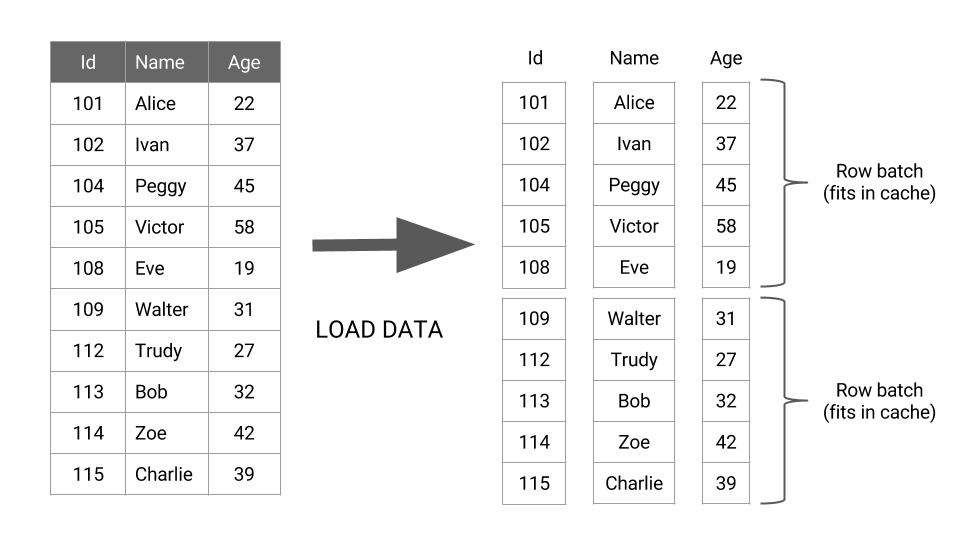
When query vectorization is enabled, the query engine processes vectors of columns, which greatly improves CPU utilization for typical query operations like scans, filters, aggregates, and joins.
Continue reading:
Enabling Hive Query Vectorization
Hive query vectorization is enabled by setting the hive.vectorized.execution.enabled property to true. Query vectorization is available in both CDH 5 and CDH 6. However, in CDH 5 vectorized query execution in Hive is only possible on ORC-formatted tables, which Cloudera recommends that you do not use for overall compatibility with the CDH platform. Instead, Cloudera recommends that you use tables in the Parquet format because all CDH components support this format and can be consumed by all CDH components. In CDH 6, query vectorization is supported for Parquet tables in Hive.
Using Cloudera Manager to Enable Query Vectorization on a Server-wide Basis
For managed clusters, open the Cloudera Manager Admin Console and perform the following steps:
- Select the Hive service.
- Click the Configuration tab.
-
Search for enable vectorization.
To view all the available vectorization properties for Hive, search for hiveserver2_vectorized. All the vectorization properties are in the Performance category.
-
Select the Enable Vectorization Optimization option to enable this feature.
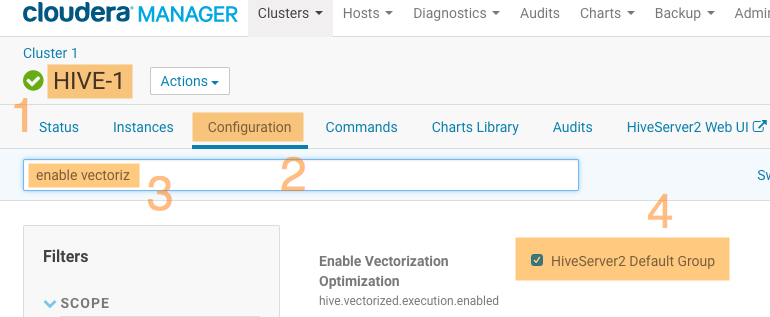
- Click Save Changes.
-
Click the Instances tab, and then click the Restart the service (or the instance) for the changes to take effect:

Manually Enabling Query Vectorization on a Server-Wide Basis
For unmanaged clusters, set the hive.vectorized.execution.enabled property manually in the hive-site.xml file to enable query vectorization on a server-wide basis:
<property>
<name>hive.vectorized.execution.enabled</name<
<value>true</value>
<description>Enables query vectorization.</description>
</property>
Enabling Hive Query Vectorization on a Session Basis
To enable query vectorization on an individual session only, use the Hive SET command:
SET hive.vectorized.execution.enabled=true;
Using the SET command to enable query vectorization on a session basis is useful to test the effects of vectorization on execution for specific sets of queries.
Tuning Hive Query Vectorization
When query vectorization is enabled, there are additional properties you can set to tune how your queries are vectorized. These properties can be set in Cloudera Manager, can be set manually in the hive-site.xml file, or can be set on a per-query basis using the Hive SET command. Use the same general steps listed in the previous section to configure these properties in Cloudera Manager or manually.
- hive.vectorized.adaptor.usage.mode
- Description: Specifies the extent to which the vectorization engine tries to vectorize UDFs that do not have native vectorized versions available. Selecting the none option specifies that only queries using native vectorized UDFs are vectorized. Selecting the chosen option specifies that Hive chooses to vectorize a subset of the UDFs based on performance benefits using the Vectorized Adaptor. Selecting the all option specifies that the Vectorized Adaptor be used for all UDFs even when native vectorized versions are not available.
- Recommendations: For optimum stability and correctness of query output, set this option to chosen.
- Default Setting: chosen
- hive.vectorized.execution.reduce.enabled
- Description: Turns on or off vectorization for the reduce-side of query execution. Applies only when the execution engine is set to Spark.
- Recommendations: Enable this property by setting it to true if you are using Hive on Spark. Otherwise, do not enable this property.
- Default Setting: true
- hive.vectorized.groupby.checkinterval
- Description: For vectorized GROUP BY operations, specifies the number of row entries added to the hash table before rechecking the average variable size when estimating memory usage.
- Recommendations: Current testing indicates that the default setting is applicable in most cases.
- Default Setting: 4096
- hive.vectorized.groupby.flush.percent
- Description: Sets the percentage between 0 and 100 percent of entries in the vectorized GROUP BY aggregation hash that is flushed when the memory threshold is exceeded. To set no flushing, set this property to 0.0. To set flushing at 100 percent, set this property to 1.0.
- Recommendations: This sets the amount of data that is held in memory. To increase performance, increase the setting. However, increase the setting conservatively to prevent out-of-memory issues.
- Default Setting: 0.1, which sets the flush percentage to 10%
- hive.vectorized.input.format.excludes
- Description: Specifies input formats to exclude from vectorized query execution. You can select org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat, org.apache.hadoop.hive.ql.io.orc.OrcInputFormat, or Custom from a drop-down list. When you select Custom, you can add another input format for exclusion, but currently no other format is supported. Vectorized execution can still occur for an excluded input format based on whether row SerDes or vector SerDes are enabled.
- Recommendations: Use this property to automatically disable certain file formats from vectorized execution. Cloudera recommends that you test your workloads on development clusters using vectorization and enable it in production if you receive significant performance advantages. As an example, if you want to exclude vectorization only on the ORC file format while keeping vectorization for the Parquet file format, set this property to org.apache.hadoop.hive.ql.io.orc.OrcInputFormat.
- Default Setting: org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat
- hive.vectorized.use.checked.expressions
- Description: To enhance performance, vectorized expressions operate using wide data types like long and double. When wide data types are used, numeric overflows can occur during expression evaluation in a different manner for vectorized expressions than they do for non-vectorized expressions. Consequently, different query results can be returned for vectorized expressions compared to results returned for non-vectorized expressions. When enabled, Hive uses vectorized expressions that handle numeric overflows in the same way as non-vectorized expressions are handled.
- Recommendations: Keep this property set to true, if you want results across vectorized and non-vectorized queries to be consistent.
- Default Setting: true
- hive.vectorized.use.vectorized.input.format
- Description: Enables Hive to take advantage of input formats that support vectorization when they are available.
- Recommendations: Enable this property by setting it to true if you have Parquet or ORC workloads that you want to be vectorized.
- Default Setting: true
- hive.vectorized.use.vector.serde.deserialize
- Description: Enables Hive to use built-in vector SerDes to process text and SequenceFile tables for vectorized query execution. In addition, this configuration also helps vectorization of intermediate tasks in multi-stage query execution.
- Recommendations: Keep this set to false. Setting this property to true might help multi-stage workloads, but when set to true, it enables text vectorization, which Cloudera does not support.
- Default Setting: false
Supported/Unsupported Data Types and Functions
Most common data types and functions are supported by Hive query vectorization on Parquet tables in CDH. The following subsections provide more details about data type and function support.
Supported/Unsupported Data Types
Currently, some complex data types, such as map, list, and union are not supported for Hive query vectorization on Parquet tables in CDH. Even though the struct data type is supported, it is vectorized only when all of the fields defined within the struct are primitives. The following data types are supported.
| int | smallint | tinyint |
| bigint | integer | long |
| short | timestamp | interval_year_month |
| boolean | binary | string |
| byte | float | double |
| void | struct | |
Supported/Unsupported Functions
Common arithmetic, boolean (for example AND, OR), comparison, mathematical (for example SIN, COS, LOG), date, and type-cast functions are supported. Also common aggregate functions such as MIN, MAX, COUNT, AVG, and SUM are also supported. If a function is not supported, the vectorizer attempts to vectorize the function based on the configuration value specified for hive.vectorized.adaptor.usage.mode. You can set this property to none or chosen. To set this property in Cloudera Manager, search for the hive.vectorized.adaptor.usage.mode property on the Configuration page for the Hive service, and set it to none or chosen as appropriate. For unmanaged clusters, set it manually in the hive-site.xml file for server-wide scope. To set it on a session basis, use the Hive SET command as described above.
Verifying a Query is Vectorized
To verify that a query is vectorized, use the EXPLAIN VECTORIZATION statement. This statement returns a query plan that shows how the Hive query execution engine processes your query and whether vectorization is being triggered.
Example of Verifying that Query Vectorization is Triggered for Your Query
This example uses the Hive table p_clients, which uses the Parquet format and contains the following columns and data types:
DESCRIBE p_clients;
⋮
+------------------+------------+----------+
| col_name | data_type | comment |
+------------------+------------+----------+
| name | string | |
| symbol | string | |
| lastsale | double | |
| marketlabel | string | |
| marketamount | bigint | |
| ipoyear | int | |
| segment | string | |
| business | string | |
| quote | string | |
+------------------+------------+----------+
To get the query execution plan for a query, enter the following commands in a Beeline session:
EXPLAIN VECTORIZATION SELECT COUNT(*) FROM p_clients WHERE ipoyear = 2009;
This command returns the following query execution plan:

Vectorization is explained in several parts of this query plan:
- The PLAN VECTORIZATION section shows a high-level view of the vectorization status for the query. The enabled flag set to true means that vectorization is turned on and the enabledConditionsMet flag shows that it is enabled because the hive.vectorized.execution.enabled property is set to true. If vectorization is not enabled, the enabledConditionsNotMet flag shows why.
- Then in the STAGE PLANS section, the output shows the vectorization status for each task of query execution. For example, there might be multiple map and reduce tasks for a query and it is possible that only a subset of these tasks are vectorized. In the above example, the Stage-1 sub-section shows there is only one map task and one reduce task. The Execution mode sub-section of the map task shows whether the task is vectorized. In this case, vectorized displays, which means that the vectorizer was able to successfully validate and vectorize all of the operators for this map task.
- The Map Vectorization sub-section shows more details of map task vectorization. Specifically, the configurations that affect the map side vectorization are shown along with whether these configurations are enabled. If the configurations are enabled, they are listed for enabledConditionsMet. If the configurations are not enabled, they are listed for enabledConditionsNotMet as explained in the above PLAN VECTORIZATION section. In this example, it shows that the map side of query execution is enabled because the hive.vectorized.use.vectorized.input.format property is set to true. This section also contains details about input file format and adaptor settings used in the map side of query execution.
- The Reduce Vectorization sub-section shows that the reduce side of query execution was not vectorized because the hive.vectorized.execution.reduce.enabled property is set to false. This sub-section also shows that the execution engine is not set to Tez or Spark, which are needed for reduce side vectorization. In this particular example, to enable reduce side vectorization, the execution engine should be set to Spark and the hive.vectorized.execution.reduce.enabled property should be set to true.
By using the EXPLAIN VECTORIZATION statement with your queries, you can find out before you deploy them whether vectorization will be triggered and what properties you must set to enable it.
| << Configuring HiveServer2 High Availability in CDH | ©2016 Cloudera, Inc. All rights reserved | Overview of Apache Hive Data Replication in CDH >> |
| Terms and Conditions Privacy Policy |